Political discourse shapes policy, and policy shapes lives. But how do politicians actually speak? What topics dominate their agendas? And do their words reflect the concerns of everyday citizens? Using NLP, we can answer these questions with data not assumptions
Introduction
Natural Language Processing (NLP) has become a central pillar of AI, especially with the rise of Large Language Models (LLMs). At its core, an LLM is just NLP applied at scale—processing massive amounts of text to generate human-like responses.
In this project, I applied NLP techniques to transcripts from the 14th convocation of the National Assembly of the Republic of Serbia. The goal was to explore political discourse in a time of heightened governmental instability (November 2024 – May 2025). The full dataset and results are available in the github repository.
Project Goals
Analyze who speaks most frequently and how they speak.
Detect recurring topics and rhetorical patterns.
Enrich political discourse with metadata and sentiment trends (ongoing work).
First step - Data collection and cleaning
If you’ve worked with real-world data before, you know the rule: 80% of the time goes to cleaning, 20% to analysis. This project was no exception.
I sourced transcripts directly from the Serbian Parliament’s official website, despite its outdated infrastructure (non-secure HTTP, expired SSL certificates). Downloads had to be manually approved due to browser warnings.
Each parliamentary session is split into several daily transcripts, so I organized them into directories by session. The files were originally in poorly structured .docx format. I converted them to .txt, then cleaned the text using regular expressions (REGEX) to extract individual speeches.
The final cleaned data was stored in JSON format:
{
"file": "2024-03-18_konstitutivna_sednica_dan2.txt",
"speaker": "MARINIKA TEPIĆ",
"speech": "Morate svima da date reč, a ne samo Aleksiću."
},
After all of that, I was ready to start the analsys.
Second step - analsys
Once the data was ready, I lemmatized and tokenized the text, saved the preprocessed corpus, and began with some visual exploration—such as word clouds and speech length analysis.
I also removed stopwords using a custom Serbian stopword list (more on that later).
Who Spoke the Most? Note: Many top speakers are session chairpersons who regularly introduce other speakers or close sessions. Their dominance in the rankings might skew the data. A future improvement could be weighting speeches differently—or filtering chairpersons out entirely.
Top Speakers
| RANK | SPEAKER | NUM OF SPEECHES | PARTY | Note |
|---|---|---|---|---|
| 1 | ANA BRNABIĆ | 1762 | SNS | Chairman |
| 2 | SNEŽANA PAUNOVIĆ | 623 | SPS | Chairman |
| 3 | MARINA RAGUŠ | 454 | SNS | Chairman |
| 4 | MILENKO JOVANOV | 328 | SNS | |
| 5 | ALEKSANDAR JOVANOVIĆ | 268 | Narodni pokret Srbije | |
| 6 | STOJAN RADENOVIĆ | 258 | SNS | |
| 7 | RADOMIR LAZOVIĆ | 125 | ZLF | |
| 8 | SRĐAN MILIVOJEVIĆ | 106 | DS | |
| 9 | MILOŠ PARANDILOVIĆ | 95 | NLS | |
| 10 | ZORAN LUTOVAC | 90 | DS | |
| 11 | MARINIKA TEPIĆ | 86 | SSP | |
| 12 | MILOŠ VUČEVIĆ | 79 | SNS | Prime minister |
| 13 | BORISLAV NOVAKOVIĆ | 77 | Narodni pokret Srbije | |
| 14 | DANIJELA NESTOROVIĆ | 74 | Narodni pokret Srbije | |
| 15 | ELVIRA KOVAČ | 57 | SVM-VMSZ | Chairman |
Speech length (No of characters)
| RANK | SPEAKER | SPEECH LEN (CHAR) | PARTY | Note |
|---|---|---|---|---|
| 1 | ANA BRNABIĆ | 799335 | SNS | Chairman |
| 2 | MILENKO JOVANOV | 696929 | SNS | |
| 3 | MILOŠ VUČEVIĆ | 482097 | SNS | Prime minister |
| 4 | SNEŽANA PAUNOVIĆ | 470949 | SPS | Chairman |
| 5 | DANIJELA NESTOROVIĆ | 283581 | Narodni pokret Srbije | |
| 6 | DUBRAVKA ĐEDOVIĆ HANDANOVIĆ | 262915 | SNS | Minister |
| 7 | ALEKSANDAR MARTINOVIĆ | 218080 | SNS | Minister |
| 8 | SINIŠA MALI | 213075 | SNS | |
| 9 | ŽIVOTA STARČEVIĆ | 151432 | JS | |
| 10 | MARINA RAGUŠ | 146521 | SNS | Chairman |
| 11 | ALEKSANDAR JOVANOVIĆ | 144590 | Narodni pokret Srbije | |
| 12 | MIROSLAV ALEKSIĆ | 141545 | Narodni pokret Srbije | |
| 13 | RADOMIR LAZOVIĆ | 138195 | ZLF | |
| 14 | MARIJAN RISTIČEVIĆ | 133678 | SNS | |
| 15 | ALEKSANDAR VULIN | 133602 | PS | Minister |
Wordcloud

Using a standard LDA (Latent Dirichlet Allocation) model, I extracted 10 dominant topics, each with 10 keywords. This approach helped identify core themes in parliamentary debates—from family policy to budget discussions and procedural language.
Topics
| Topic # | Top Words | Probable Theme | Interpretation |
|---|---|---|---|
| 0 | zakon, godina, srbija, imati, hteti, ministarstvo, obrazovanje, građanin | Public Policy & Legislation | General discussion of laws, government ministries, and citizens’ rights, likely around national policy or legal reforms. |
| 1 | litijum, rudnik, tinto, sredina, zakon, projekt | Environmental Concerns & Lithium Mining | Focused on Rio Tinto, lithium mining, and its impact on the environment and legislation. |
| 2 | srbija, republika, razvoj, država, zemlja | National Development & Strategy | Talk of Serbia’s development, government, and national identity. High-level political or economic strategy themes. |
| 3 | hteti, čovek, imati, kazati, vlada, govoriti | Political Rhetoric & Governance | Speeches reflecting personal appeals, leadership intentions, and critiques of governance. |
| 4 | porođaj, porodiljski, bolovanje, trudan | Maternal & Family Policy | Centered around maternity, childbirth, and family leave policies. Likely from social/health policy discussions. |
| 5 | imati, hvati, izvoliti, narodni, poslanik | Parliamentary Procedure & Formalities | Language typical in formal sessions — calling on MPs, presence, and formal phrases. Possibly procedural or ironic. |
| 6 | privoditi, kraj, isteklo, reklamiranje, potpredsednica | Session Closure & Miscellaneous | A mixed set likely from session endings, odd terms, and possibly sarcastic or humorous remarks. |
| 7 | godina, evro, milion, milijarda | Budget & Economy | Financial discussion — budget, expenditures, and national economic outlook. |
| 8 | narodni, poslanik, amandman, glasanje, zakon | Legislative Process & Amendments | Focused on voting, proposing laws, and parliamentary decision-making. Core legislative procedures. |
| 9 | poslovnik, replika, vreme, kazati | Debate Rules & Floor Management | Deals with speaking time, requests, and adherence to parliamentary rulebook — classic floor debate content. |
Sentiment analsys
Sentiment analysis in Serbian is a real challenge. Most tools are designed for English, Chinese, or Spanish—leaving low-resource languages behind. So, I created a custom sentiment lexicon for Serbian using the NRC Emotion Lexicon by Saif Mohammad.
I mapped each English word with a Serbian translation, removed the English column, and built separate datasets for Latin and Cyrillic scripts.
Here’s an example output from one party’s emotional tone:
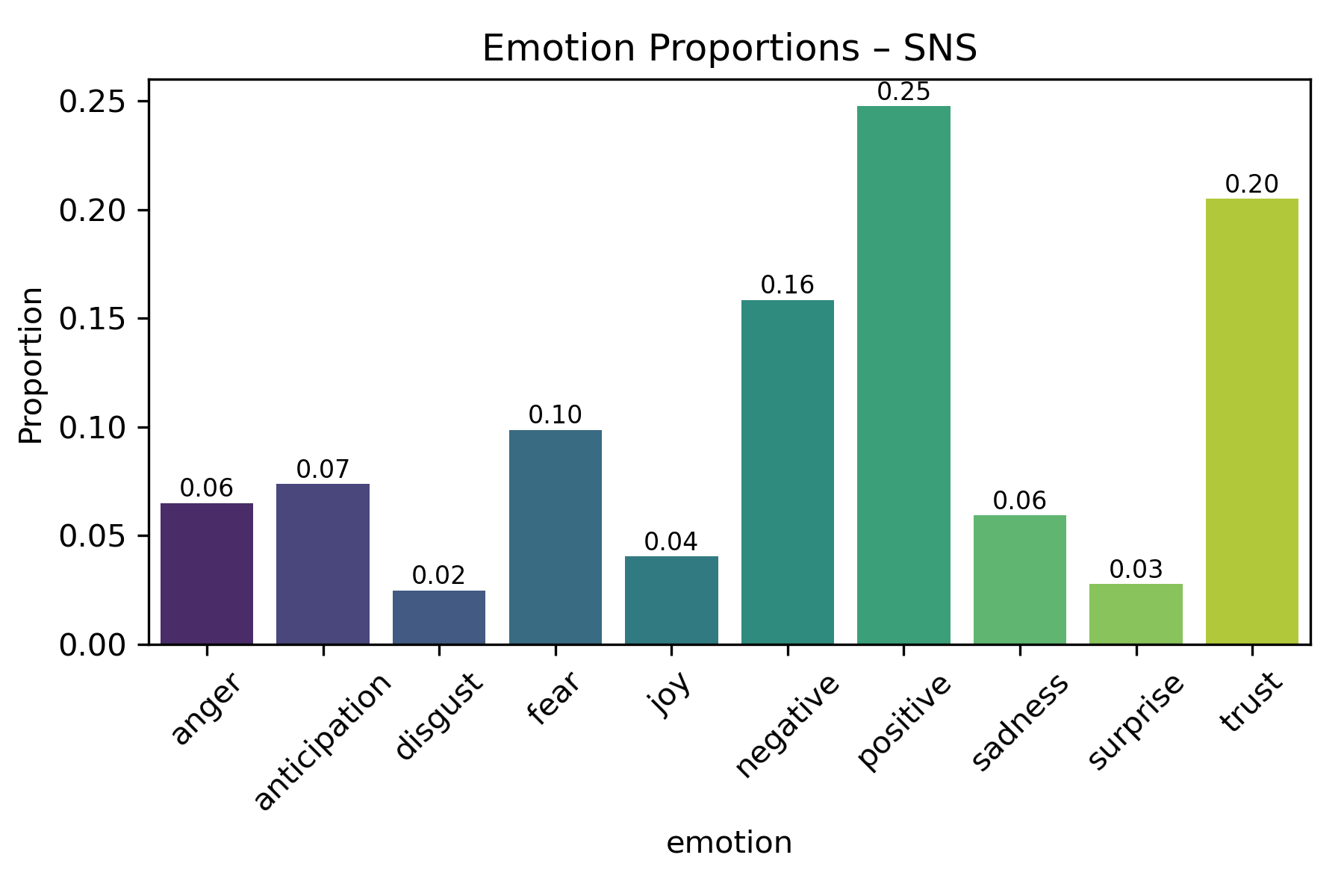
The Stopwords Problem
No high-quality Serbian stopword lists? No problem. I built one manually. My method:
- Extract most frequent words.
- Filter out low-information words (often 3 letters or fewer).
- Reiterate until the list made sense.
- Create separate lists for Latinica and Ćirilica.
- For sentiment analsys, I relied on Saif Mohammad work in NRC Word-Emotion Association Lexicon. If you are interested, the dataframes with stopwords and sentiment scores are here.
Conclusion & Future Work
This project is just a beginning. I plan to:
- Improve sentiment classification using Serbian-specific transformers.
- Incorporate speaker embeddings and unsupervised clustering (e.g., UMAP).
- Build interactive dashboards for public access. If you’re a researcher, developer, or just curious about NLP and politics feel free to fork the repo, suggest improvements, or collaborate!